프로젝트 구성
컴퍼레이 프로젝트 주요 구성 요소와 그 세부 내용을 소개합니다.
컨벤션을 효과적으로 지원하는 모델 구성과 배포 방식을 명확히 설명합니다.
모델
컴퍼레이는 높은 품질의 결과와 대기시간 단축을 위해 미세조정된 모델을 사용합니다.
gpt-3.5.turbo-1106 모델을 사용하며, 1,027,240 토큰이 학습에 사용되었습니다.
현재 모델은 1.0.0 버전입니다. 추후 연구 및 개발을 통해 업데이트 예정입니다.
모델 버전이 변화할 때 마다 본 문서도 함께 업데이트되어 최신 정보를 반영합니다.
데이터 세트
1,124개의 git diff 명령어 결과를 챗 지피티 대화형 형태로 학습시켰습니다.
코드 변경 사항을 읽고, 설명하는 커밋 메시지를 작성하도록 구성되어 있습니다.
{
"messages": [
{
"role": "system",
"content": "Write a commit message based on the git diff. You must read line by line and understand the changes made in the code. Write a commit message that describes the changes made in the code."
},
{
"role": "user",
"content": "diff --git a/DIRECTORY.md b/DIRECTORY.md\nindex 11e03f2..d839f53 100644\n--- a/DIRECTORY.md\n+++ b/DIRECTORY.md\n@@ -38,6 +38,7 @@\n * Projecteuler\n * [Problem1](./Maths/ProjectEuler/Problem1.php)\n * [Problem10](./Maths/ProjectEuler/Problem10.php)\n+ * [Problem11](./Maths/ProjectEuler/Problem11.php)\n * [Problem2](./Maths/ProjectEuler/Problem2.php)\n * [Problem3](./Maths/ProjectEuler/Problem3.php)\n * [Problem4](./Maths/ProjectEuler/Problem4.php)\n@@ -46,7 +47,6 @@\n * [Problem7](./Maths/ProjectEuler/Problem7.php)\n * [Problem8](./Maths/ProjectEuler/Problem8.php)\n * [Problem9](./Maths/ProjectEuler/Problem9.php)\n- * [Problem11](./Maths/ProjectEuler/Problem11.php)\n \n ## Searches\n * [Binarysearch](./Searches/BinarySearch.php)"
},
{
"role": "assistant",
"content": "Add Problem 11 to Project Euler directory\n\n- Added link to Problem 11 in the Project Euler section of DIRECTORY.md\n- Ensured the removal of a duplicate or misplaced link to Problem 11"
}
]
}
모델 학습
전처리된 데이터 세트로 모델을 학습시키고, 최적의 성능 도출을 위한 파라미터입니다.
| 파라미터 | 값 | 설명 |
|---|---|---|
| Epochs | 1 | 데이터 세트 학습 횟수를 의미합니다. 값이 높을 수록 모델이 더 많이 학습하지만, 과적합의 위험이 있습니다. |
| Batch Size | 1 | 한 번의 학습 단계에서 사용되는 데이터 샘플의 개수를 의미합니다. 값이 높을 수록 메모리 사용량이 증가하지만, 안정적인 손실 값이 나옵니다. |
| Temperature | 0.1 | 모델이 생성하는 텍스트의 무작위성을 제어하는 파라미터입니다. 값이 낮을 수록 고정되고, 값이 높을 수록 다양하고, 창의적인 결과가 생성됩니다. |
| Top P | 0.5 | 확률 분포의 상위 p 확률을 합한 것이 p보다 작거나 같은 토큰들만 고려하여 단어를 생성하는걸 의미합니다. |
| Presence Penalty | 0 | 텍스트 생성 과정에서 특정 단어의 반복성을 제어하는 파라미터입니다. 특정 단어가 자주 등장하면 패널티를 부여하여 다양성을 높입니다. |
| Frequency Penalty | 0 | 텍스트 생성 과정에서 특정 단어의 빈도를 제어하는 파라미터입니다. 특정 단어가 자주 등장하면 페널티를 부여하여 다양성을 높입니다. |
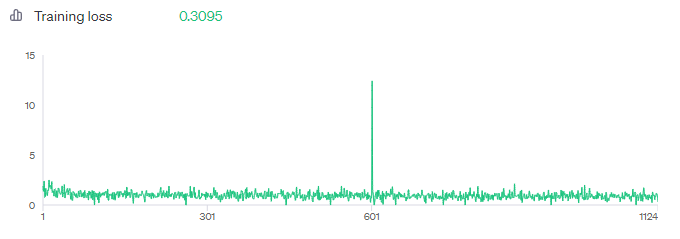
결과
최종적으로 학습 결과 $8.23 비용으로 0.3095의 손실률을 기록하였습니다.
소모된 비용은 공식을 통해 도출되었습니다.
지속적인 개선과 업데이트를 통해 더욱 정확하고 효율적인 모델을 제공할 것입니다.
모델 사용 비용은 100만개 토큰에 대해 입력 값으로 1.5가 지불됩니다.
대략 3000자의 입력에 대해 입력 1000개, 출력 100개의 토큰이 소모됩니다.
이는 1회 기준 약 $0.00065 비용을 ChatGPT OpenAI 측에 지불하게 됩니다.
서비스
컴퍼레이는 Next.js 기반으로 Vercel 호스팅을 통해 서비스합니다.
별도의 추가적인 데이터를 관리하고 있지 않으므로, 데이터베이스는 없습니다.
환경 변수
서비스 배포 시 .env 파일에 관리되는 필수적인 빌드 환경변수 데이터입니다.
| 키 | 설명 |
|---|---|
| GPT_KEY | ChatGPT에서 API 사용을 위해 발급하는 SECRET KEY 입력 부분입니다. openai api-keys에 접근하여 발급받을 수 있습니다. |
| GPT_MODEL | ChatGPT의 사용할 모델을 정의합니다. 파인튜닝 된 경우 고유의 아이디 값을 입력하여 사용합니다. |
| GPT_SYSTEM | 원하는 입력 혹은 출력 형태를 명시하기 위해 사용되는 대화형 채팅 형식입니다. |